
Q. Что такое SAP HANA?
A. SAP HANA это база данных, работающая на технологи In-memory
- Это комбинация оборудования и ПО, спроектированная, чтобы обрабатывать большие массивы данных в реальном времени, используя технологию In-memory
- Она сочетает в себе технологию постолбцовой и построчной обработки данных
- Данные находятся в основной памяти (RAM), а не на жестком диске
- Эта технология главным образом подходит для обработки и аналитики данных в режиме реального времени, разработки и развертывании приложений, так же работающих в реальном времени
Понятие «База данных In-memory» означает, что все данные хранятся в оперативной памяти (RAM). Теперь не затрачивается время на загрузку данных с жесткого диска или на обработку данных, часть которых хранится на жестком диске, а часть в оперативной памяти. Все данные хранятся в памяти все время, что придает процессору дополнительную быстроту при работе с данными.
SAP HANA оснащен разветвленной средой обработки процессов, которая поддерживает как обработку графической, так и текстовой информации одной системой. Он также обеспечивает значительное ускорение обработки процессов, работу с большими массивами данных и глубокий анализ текста.
Q. SAP поставляет ПО или оборудование?
A. SAP сотрудничает со многими известными производителями оборудования (HP, Fujitsu, IBM, Dell), чтобы поставлять сертифицированное оборудование для HANA. SAP также продает лицензии и связанные с SAP HANA услуги, включающие в себя базы данных SAP HANA, SAP HANA Studio и прочее ПО для работы с базами данных.
Q. На каком языке написан SAP HANA?
А. SAP HANA написан на С++
Q. Какую ОС поддерживает SAP HANA?
А. Сейчас SAP HANA поддерживает SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1
Q. Могу ли я просто увеличить размер оперативной памяти до 2ТВ и получить похожую производительность?
А. Нет. Вы, безусловно, получите ускорение в работе за счет увеличения объема оперативной памяти, но SAP HANA — это не просто база данных с большим объемом оперативной памяти. Это сочетание множества технологий взаимодействия между ПО и оборудованием. Увеличение объема оперативной памяти — это лишь верхушка айсберга.
Q. Что означают столбцовый и строчный подход в хранении данных?
А. Строчный подход – это работа с традиционными базами данных, которые хранят данные в последовательности строчек.
Столбцовый подход — данные хранятся в последовательности столбцов в постоянных местах. SAP HANA особенно хорошо работает со столбцовым подходом.
SAP HANA поддерживает оба подхода обработки данных. Таблица объясняет разницу между двумя способами.
Q. В чем преимущества и недостатки строчного подхода?
А. Преимущества:
- Приложениям нужно обрабатывать только одну запись за один подход (множественный выбор и/или обновления единичных записей)
- Приложениям обычно требуется доступ к полной записи (строке)
- Не требуются ни быстрый поиск, ни агрегация данных
- Таблица состоит из небольшого количества строк (например, таблицы конфигурации и системные таблицы
Недостатки:
- В случаях работы аналитических приложений, использующих агрегацию и быстрый поиск, построчный подход подразумевает обработку всех содержащихся в таблице данных, несмотря на то, что требуется обработать лишь их часть
Q. В чем преимущества столбцового подхода?
А. Преимущества
Ускоренный доступ к данным. Обрабатываются только необходимые ячейки. Любые ячейки могут содержать вспомогательную информацию.
Улучшенное сжатие. Столбцовые таблицы допускают значительное сжатие из-за того, что большинство столбцов хранят только несколько значений.
Улучшенная параллельная работа с такими таблицами. В столбцовом хранении данные имеют вертикальное разделение. Это значит, что операции над разными колонками с легкостью могут протекать параллельно. Если должно быть обработано множество столбцов одновременно, то каждый процесс обработки может задействовать ЦП.
Q. С каким типом таблиц HANA работает лучше?
А. Запросы SQL, затрагивающие сложные функции, отнимают много времени по причине неоходимости обработки каждой ячейки. В столбцовых таблицах данные хранятся фактически рядом, что значительно влияет на ускорение обработки запроса. Также, хорошо сжатые данные обеспечивают дополнительное ускорение обработки.
Заключение. Для обеспечения быстроты обработки, формирования отчетов и пользы от прекрасного сжатия рекомендуется использовать столбцовую технологию хранения данных.
SAP HANA позволяет сочетать строчный и столбцовый подход. Однако более эффективно будет объединять одноименные подходы.
Несколько важных вещей о столбцовом подходе:
- Моделирование вида в HANA возможна только в столбцовых таблицах.
- По этой причине сервер копирования данных создает по умолчанию столбцовую таблицу HANA
- Сервисы данных также по умолчанию создают столбцовые таблицы для баз данных SAP HANA
- Команда SQL для создания столбцовой таблицы «CREATE COLUMN TABLE Table_Name..»
- Тип хранения данных в таблицы может быть преобразован из строчной в столбцовую SQL-командой «ALTER TABLE Table_Name COLUMN»
Q. Почему в HANA не требуются материализованные соединения?
А. Так как база данных SAP HANA постоянно находится в оперативной памяти (технология In-memory), дополнительные сложные расчеты, вычисления и прочие операции над данными могут происходить непосредственно в базе данных. Следовательно, материализованные соединения не требуются. Это также несет следующую пользу:
- Упрощенная модель данных
- Упрощенная логика приложений
- Высокий уровень параллельности
Q. Как SAP HANA поддерживает параллельное высчисление в больших массивах?
А. С доступностью многоядерных процессоров стала доступна и высокая степень производительности.
Также столбцовое хранение данных HANA делает доступным параллельное выполнение операций, используя многоядерные процессоры. В столбцовом хранении данные уже вертикально поделены. Это означает, что операции с разными столбцами могут приходить параллельно. Если поиск или другие операции должны быть произведены над множеством столбцов, то каждый такой процесс может обращаться к отдельному ядру процессора. В дополнение операции над одной колонкой могут быть разбиты на параллельные процессы, каждый из которых в свою очередь будет работать с отдельным ядром процессора.
Q. Почему SAP HANA такой быстрый?
А.
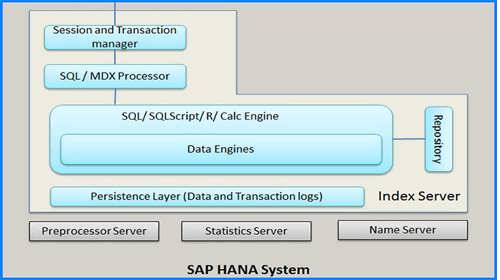
Q. Опишите архитектуру базы данных SAP HANA
База данных SAP HANA разработана в среде С++ и работает на SUSE Linux Enterpise Server. База данных SAP HANA состоит из множества серверов, главной частью которых является сервер указателей. База данных SAP HANA делится на сервер указателей, сервер имен, сервер статистики, сервер препроцессора и движок XS.
Сервер указателей
- Сервер указателей – основной компонент базы данных SAP HANA
- Он содержит хранилища актуальных данных и движки для их обработки
- Сервер указателей работает с входящими SQL-запросами или выражениями MDX в контексте подтвержденных сессий и транзакций.
Постоянный слой
- Постоянный слой базы данных отвечает за надежность и множественность транзакций. Он гарантирует, что база данных может быть восстановлена после перезагрузки до последнего стабильного состояния и что нет незавершенных или недозавершенных транзакций.
Сервер препроцессора
- Сервер указателей использует сервер препроцессора для анализа текстовых данных и извлечения информации, на которой основаны возможности поиска в тексте
Сервер имен
- Сервер имен хранит информацию о топологии в системе SAP HANA. В распределенной системе сервер имен знает какие компоненты задействованы и на каком сервере расположены определенные данные
Сервер статистики
- Сервер статистики собирает информацию о статусе, производительности и потреблении ресурсов различными серверами и приложениями. Сервер статистики также историю измерений для дальнейшего анализа.
Менеджер сессий и транзакций
- Менеджер транзакций координирует транзакции базы данных и сохраняет список исполняемых и выполненных транзакций. Когда транзакция отклоняется или не может быть исполнена и возвращается, менеджер транзакций извещает соответствующий движок хранилища об этом для выполнения дальнейших действий.
Движок XS
Движок XS — дополнительный компонент. Используя его, клиенты могут подсоединяться к базе SAP HANA через HTTP
Q. Что такое анализ ad-hoc?
А. Традиционные хранилища данных, такие как SAP BW совершают множество операций, чтобы обеспечивать быстрые результаты работы. IT департамент решает, какая именно информация понадобится для анализа и готовит результат для конечных пользователей. Эти результаты быстродейственны, но не гибки в использовании пользователями. Быстродействие значительно снижается, когда пользователь хочет произвести анализ данных, которые не были предварительно обработаны. С SAP HANA и его скоростным движком предварительной обработки не требуется. Пользователь может производить любые виды операций с данными и не ждать часами их результата.
По материалам http://saphanatutorial.com/
Вам может быть интересно






Оставить комментарий
Подпишитесь на рассылку статей.
Не волнуйтесь, мы не spam
0 Комментариев